

Welcome to the Opioid Industry Documents Archive (OIDA) Toolbox! This page is designed to help you access the raw data behind OIDA, a digital archive co-created by the University of California, San Francisco and Johns Hopkins University containing millions of documents from the opioid industry that shed light on the root causes of the opioid crisis.
By “raw data” we mean metadata describing the documents, the documents themselves in various file formats, and text extracted from the documents. As described below, the raw data are available through SciServer and Amazon Simple Storage Service (Amazon S3), and the metadata can be queried and downloaded in bulk through the Industry Documents Library (IDL).
| Feature | SciServer | Prepared datasets from IDL | AWS | Internet Archive | IDL Solr API |
|---|---|---|---|---|---|
| Query metadata and full text | Yes | – | Yes (using Parquet) | – | Yes |
| Download metadata | Yes | Whole collections | Yes (in Parquet format) | Yes | Yes |
| Download full text | Yes | Whole collections | Yes | – | – |
| Download native formats and page images | Yes except audio and video | No | Yes except audio and video | Audio and video | – |
| Sample notebooks/code | Available: showing flexible query via Solr API and bulk downloading, plus basic text analysis and visualization | – | – | – | Access and sample code provided |
| Environment | Cloud-based (everything included) | – | Bring your own cloud instance | Command line or Python | API-based |
| File system access | Yes | – | Yes | – | – |
| Metadata formats | Parquet (plus other formats through Solr API) | – | Parquet only | XML and SQLite | XML, JSON, Python, Ruby, PHP, and CSV |
| “Batteries included” | High (cloud-based, ready to use) | Medium (prepared datasets) | Low (requires own setup) | Medium (basic technologies) | Medium (API access) |
Johns Hopkins students and staff can also access and compute on raw data through the DISCOVERY HPC (high-performance computing) cluster.
Due to the need to ensure integrity and appropriate redaction of newly released documents, there can be a delay of a few weeks between when documents are released on the IDL website and when they are available in the OIDA Toolbox as raw data.
Need help beyond what’s below? Please contact [email protected]
What can you do with OIDA data?
Applying computational methods to the documents in OIDA can provide valuable insights into the documents and the opioid crisis. For example:
- Machine learning and data mining can help reveal hidden patterns, trends, and correlations within the archive, such as how actions by specific people correlated with changes in opioid prescription rates in different regions.
- Social network analysis can reveal the connections among employees of a company and between doctors, sales reps, pharmacists, drug distributors, and regulators. It can reveal who communicated with whom most frequently, and during which time periods, helping us understand how communication and decision-making work in a large organization.
- Natural language processing and other linguistic analysis allows for study of written communication in the modern workplace and in relation to specific actions of these companies.
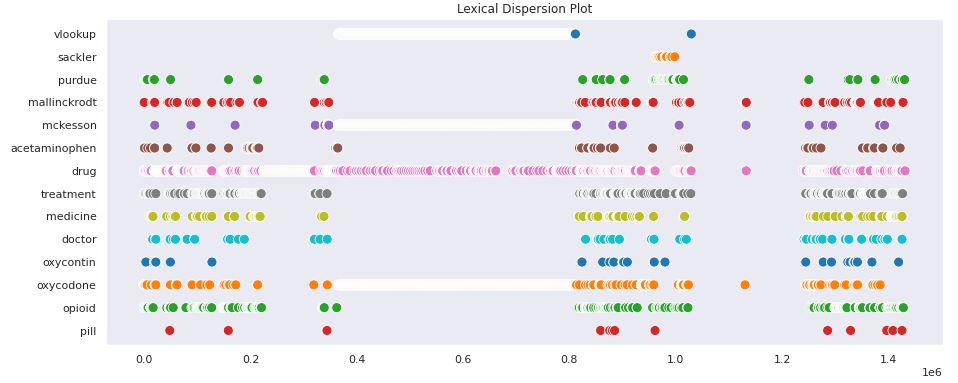
Here is a lexical dispersion plot for a list of common terms in OIDA as found in a sample of 1,000 documents and generated using one of the sample Jupyter notebooks provided through SciServer.
Work in your browser with SciServer
You can work with OIDA’s metadata, documents (except audio and video), and extracted text using SciServer, a web-based sandbox for server-side analysis with extremely large datasets using interactive Jupyter notebooks. We provide sample notebooks that allow you to accomplish a commonly requested task: retrieving a list of OIDA documents matching a query and then downloading those documents for offline use (see a sample set of 4 documents). We also provide a notebook that shows how to perform some basic text analysis and visualization on a sample of 1,000 documents.
SciServer does not require installing additional software beyond a web browser nor downloading big datasets, but working with OIDA’s sample Jupyter notebooks does require some basic familiarity with Python. For performing additional data analysis, SciServer provides users with a virtual machine image in the cloud, pre-installed with Python and important data analysis packages (including Pandas, NumPy, and SciKit-Learn).
Getting started
See Getting Started with OIDA and SciServer for how to get access to OIDA data through SciServer and use our Jupyter notebooks within SciServer for downloading files that match a query and for performing basic text analysis and visualization. You can edit these notebooks to adapt them to your needs. We welcome your suggestions for additional notebooks we might create to help you get started with analyzing OIDA’s raw data; please reach out to us at [email protected]
Download full text and metadata for OIDA collections
If you want the full text of OIDA documents (but not the page images, PDFs, and native file formats) along with associated metadata for one or more collections within OIDA, the simplest option for getting these is to download the appropriate collection-level ZIP file(s) from the IDL.
Download from and work with data on AWS
OIDA’s raw data (except audio and video) is made available through the AWS Open Data Sponsorship Program: see our entry on the Registry of Open Data on AWS. OIDA data can be downloaded for local use or used in the cloud with products such as AWS SageMaker and Google CoLab.
For more information, see the documentation for OIDA Data on AWS. We welcome your suggestions for how to improve our documentation. Please reach out to us at [email protected]
Download audio and video from the Internet Archive
OIDA’s audio and video files are stored in IDL collections in the Internet Archive:
The Internet Archive provides two methods for bulk downloads of content.
Directly query the Industry Document Library’s Apache Solr server
Many metadata fields for documents in OIDA (and the rest of the IDL), plus the full text appearing in documents, can be searched using the IDL’s Solr API. Metadata for matching documents can be retrieved in these formats: XML, JSON, Python, Ruby, PHP array, and CSV.
Metadata for individual documents
To access a document’s metadata, query the IDL’s Apache Solr server with the document’s ID. This unique, 8-character alphanumeric ID consists of four letters followed by four digits, e.g., flpp0234.
For example, to return the information of the document with ID flpp0234https://metadata.idl.ucsf.edu/solr/ltdl3/query?q=id:flpp0234. The default response returns XML data.
Searching the full text of documents
The same basic query structure can be used to keyword search all OIDA and retrieve metadata about matching documents. For example, to search for the word “addiction” in all OIDA documents within the IDL, use the following: https://metadata.idl.ucsf.edu/solr/ltdl3/query?q=(addiction AND industry:Opioids).
Additional metadata fields can be added with Boolean logic for advanced searching. For more information and further examples, please see the IDL’s Solr API documentation.
Work in DISCOVERY HPC (Johns Hopkins students and staff only)
Johns Hopkins affiliates can access and analyze the raw data through the DISCOVERY high-performance computing cluster, seamlessly integrating OIDA data into their existing HPC workflows. Like SciServer, DISCOVERY provides an HPC environment with popular research tools including Python, RStudio, MATLAB, JupyterLab, and VS Code while also offering GPU resources for Hopkins users.
Please contact us at [email protected] to discuss access options.
Have you used OIDA data?
We’d love to hear from you about how you’ve used OIDA data and possibly share your work with others on this website! Please reach out to us at [email protected]
Get updates about the OIDA Toolbox
Want to receive occasional emails about new tools and features in the OIDA Toolbox? Please contact us at [email protected] to be added to our mailing list.
The OIDA Toolbox has been made possible in part with support from the UCSF-JHU Opioid Industry Documents Archive.